
I built an AI newspaper that runs itself every morning
I did it to learn about the community my kids play sports in. And It's working!


At 6am, the harvest agent wakes up and crawls every source I’ve pointed it at — local news sites, organization pages, RSS feeds. It pulls everything football-related into a staging table and tracks which sources keep delivering and which ones have gone dry.
At 7am, the curator agent reads everything harvested in the last 26 hours, checks it against every story ever published — all-time deduplication — and asks Claude Sonnet to pick the single best story. The editorial agent constraint narrows it down to one.
At 8am, the broadcast agent reads today’s published digest and sends it out via email.
Once a week, a separate discovery agent goes looking for new sources. It searches the web, checks RSS feeds on organization sites, and uses a small language model to score whether each candidate is actually relevant. Good ones get added to the crawl list automatically.
I don't touch it. I don't even know what the story is until I read my own email.
It’s Pitch Digest — the editorial layer of PitchRoots, a community football information platform I’ve been tinkering with. One story per day. No feed. No noise.
I built it because I don't know anything. My son plays football in Spruce Grove and I always feel like I am disoriented with the broader Edmonton football ecosystem — how Tiers work, which clubs cater to which players, and when tournaments and training programs kick off. I built Pitch Digest to keep me in the loop about football related people, places, and events.
Pitch Digest is a four-stage pipeline. Each stage is its own agent, running on its own schedule. Four agents. Four cron schedules. Zero human intervention on a normal day.
What makes this reliable enough to leave it unattended?
If you've ever built something like this — a multi-step workflow where each step calls an API, writes to a database, or invokes an LLM — you know the failure mode. Step three fails. You retry the whole thing. Step one re-crawls the web. Step two re-processes everything. Your LLM bill doubles. Or worse: step three partially completes, you retry, and now you've got duplicate data.
The AI part works. The plumbing breaks constantly. Network timeouts. Rate limits. Cold starts. Partial writes. Every step is a new opportunity for the whole thing to fall apart.
And this is a daily pipeline. If it breaks on Tuesday and I don't notice until Thursday, that's two days of silence.
I outsourced all of that stress to Resonate.
Resonate is a durable execution engine. It tracks the progress of each step in a workflow and guarantees that if something fails, it picks up exactly where it left off. From the failed step, not the beginning.
Each agent is a generator function. Every step yields a durable checkpoint.
The curator agent, for example, has five steps: check if a digest was already published today, load the recent harvest, load the dedup list, ask Claude to pick a story, and publish it. Each of those steps is individually durable. If the LLM call in step four times out, Resonate retries step four. Steps one through three don't re-execute — their results are already stored.
On resume, completed steps replay instantly from server state. No re-execution, no duplicate writes. The generator pattern makes this natural — you write your workflow as a straight-line sequence of steps, and the durability layer handles the rest.
It spins up. It processes work. It spins down.
These agents run on Supabase Edge Functions — serverless, pay-per-invocation. Resonate's HTTP-push mode sends execution callbacks to each function endpoint. The agents don't poll. They don't hold connections open. They wake up, do their work, checkpoint progress, and go back to sleep.
The whole thing costs almost nothing to run. Four functions, four cron triggers, a few LLM calls per day. The infrastructure matches the workload: bursty, short-lived, cheap at rest.
Everything can be serverless because Resonate handles the state. All the durability, progress tracking, and retry logic lives on the Resonate server. The functions just do work and yield results.
And Resonate offers a great observability.
Every promise in Resonate has a state — pending, resolved, rejected — along with its input, output, timestamps, and its position in the call hierarchy. That's not logging I added. That's just what durable promises are. The execution history is the observability layer.
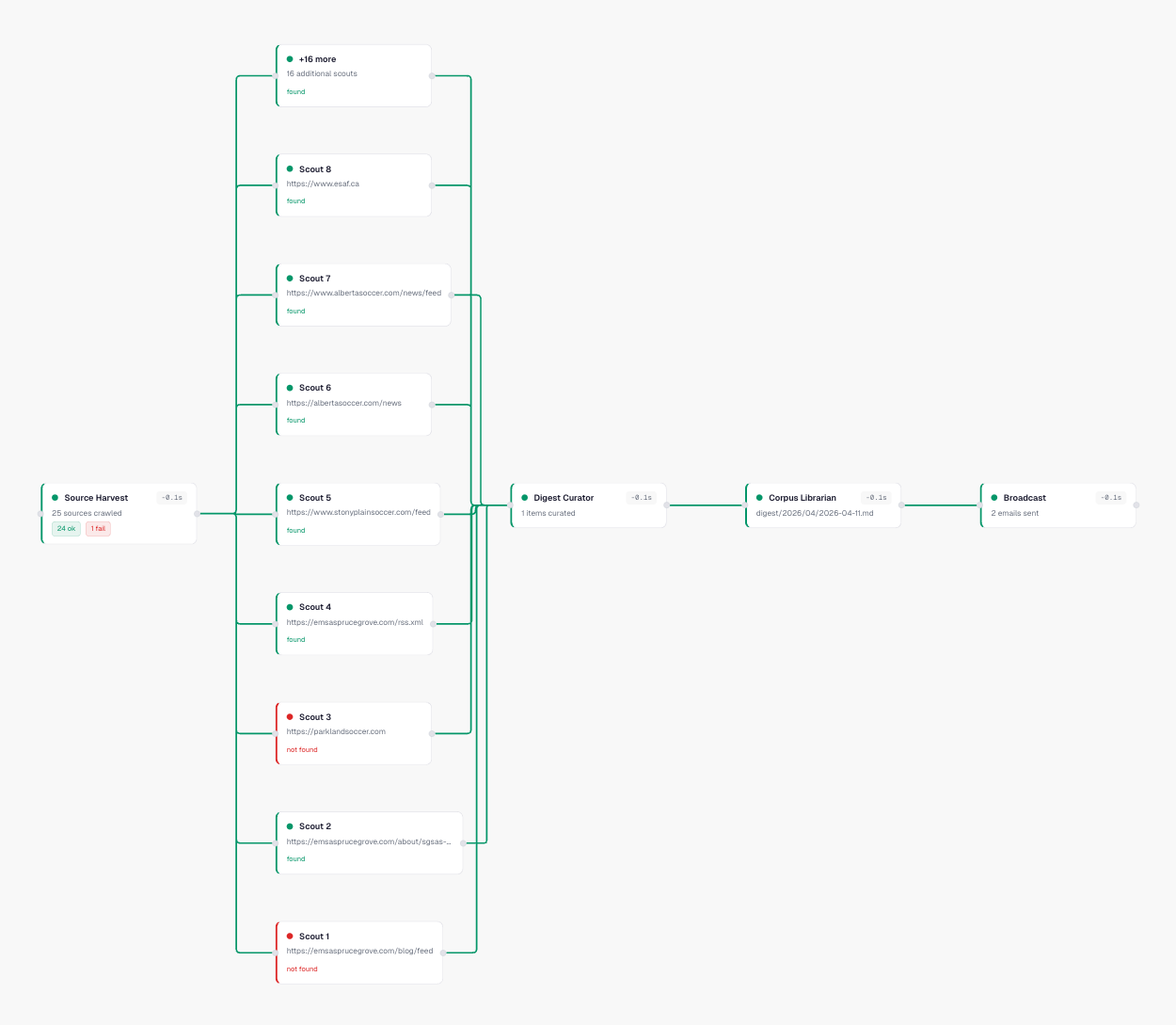
This is the call graph for a single morning's pipeline run. Source Harvest fans out into individual scout promises — one per source URL. Each scout shows whether it found new content or came back empty. Green means it delivered. Red means the source was down or had nothing new. The pipeline flows left to right: harvest → curator → corpus librarian → broadcast. Every node shows its duration.
I didn't instrument this. I didn't add tracing spans or wire up OpenTelemetry. The promise tree is the trace. Resonate tracks every function invocation as a promise in a parent-child hierarchy, so the call graph builds itself.
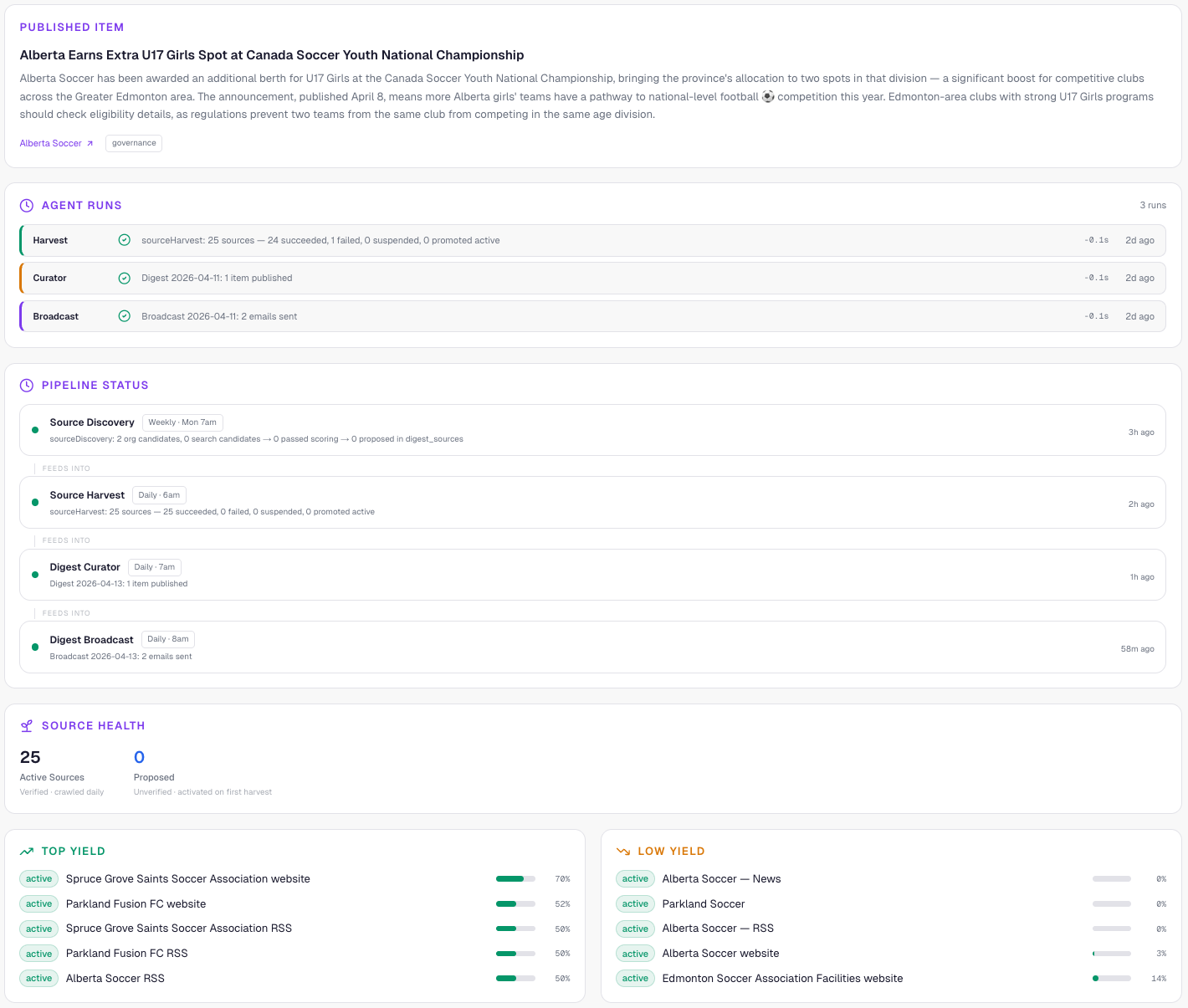
The dashboard pulls from the same promise data. Today's published story at the top. Pipeline status showing whether each agent succeeded, failed, or hasn't run yet. Source health tracking which of the 25 sources are producing and which have gone dry — so I can see at a glance if a source needs to be dropped or investigated.
With most pipeline architectures, you'd bolt on a separate observability stack — custom dashboards, log aggregation, the works. Correlation IDs, trace contexts, status pages. A whole second project.
With durable promises, the execution model itself is queryable. Every promise has a known state. Every parent-child relationship is tracked. You just read the data that's already there.
The hard part of an AI editorial pipeline isn't the AI. Claude is genuinely good at picking stories and writing summaries. The hard part is everything around it — making sure the harvest actually ran, making sure a failed broadcast doesn't silently eat the whole day's output.
Durable execution turns those problems from "things I have to monitor and manually fix" into "things the system handles."
The pipeline has been running for weeks now. I check in occasionally. It just works.
That's the bar for anything I want to run unattended. Not "it works when everything goes right." It works when things go wrong, and I don't have to know about it.
And the best part? Here are four real headlines my own tool brought me in its first week:
Alberta Communities Invited to Bid on Hosting Canada Soccer National Championships Through 2029
Spruce Grove Soccer Hosting Free Grassroots Coaching Courses This Month — Spots Still Available
Alberta Earns Extra U17 Girls Spot at Canada Soccer Youth National Championship
Women’s Football ⚽ Takes the Big Screen: ‘The Pitch’ Screens in Edmonton This Tuesday
I built this to learn about the community my kids play sports in. And It's working!
This is all pretty much above my head, but what can glean impresses the hell out of me.